Please send feedback to any of the authors and cc: ckrm-tech_at_lists.sf.net.
The latest version of the document will be kept at http://ckrm.sf.net. This document is dated 04/20/2006.
Class-based Kernel Resource Management (CKRM) is a set of modifications to the Linux kernel to enable resource management. The key idea in CKRM is to control and monitor system resource usage through user-defined groups of kernel objects called classes. Classes can be defined to distinguish between applications, workloads and users in their usage of any system resource such as CPU ticks, physical pages, disk I/O bandwidth, number of open file handles, number of tasks etc.
By default, class is inherited by children. User can explicitly move a task between classes. User can also use the Classification Engine, explained later, to automatically classify tasks into different classes.
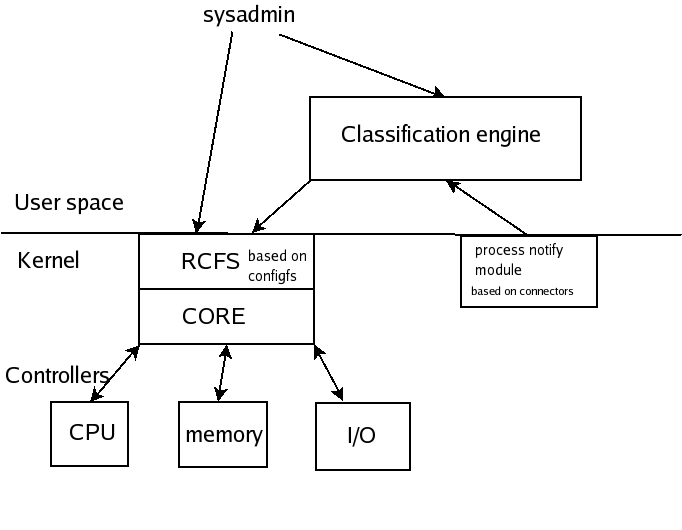
CKRM components are as shown above:
This component has three roles. First, it defines the user API consisting of configfs based interface alled RCFS (Resource Control File System). Second, it defines the API between itself and resource controllers. Thus the core acts as the switchboard for users and resource controllers to interact. Finally, core handles the creation and management of classes. When we say Core, CKRM or CKRM Core, we refer to this core infrastructure.
Currently CKRM only handles the management of tasks.
These components provide differentiated access to specific resources. There can be multiple RCs defined simultaneously managing different resources. The CKRM project currently provides CPU (ticks), Memory (physical page frames), I/O (disk bandwidth) and Number of Tasks resource controllers. Resource controller could either be a module or compiled in. At compile time one could choose the controllers they want in their kernel.
Every Resource controller must adhere to the Core-RC kernel API defined in the data structure ckrm_controller.
This component does automatic classification of tasks into classes based on user needs. CE is in user space and uses Process Event connector to get notification of events (like fork() exec() etc.,) of a task and can classify the task to appropriate class at those events.
CKRM project provides a rule-based classification engine (RBCE) that performs classification by evaluating a set of rules entered by a privileged user.
A class, is a collection of tasks, with an associated set of shares and usage statistics for each managed resource in the system. A managed resource (such as CPU, physical memory and disk I/O) is one whose scheduler or controller is class-aware.
Each class is associated with a lower and upper bound of resource usage, called min_shares and max_shares, for each managed resource in the system. min_shares and max_shares are unitless. The absolute amount of resource a class depends on the proportion of child's shares w.r.t parent's CHILD_TOTAL_DIVISOR. More details in Section 2.5. The two are collectively called a share where the distinction is unimportant.
Each task in the system always belongs to a class. The main principle behind CKRM is that a task's consumption of managed resources is controlled (using shares) and monitored (available as class' statistics) primarily through the task's class.
Association of tasks to classes is dynamic. A task's classification can be changed either manually as described Section 2.7, or automatically using a classification engine as described in Section 4.0.
Classes are primarily used by sysadmins to monitor and control the resources used by various workloads running on a system e.g. mailserver, apache, dns etc. It can also be used to limit and track resource usage of users.
In both these cases, it is useful to allow the application or user to manage its own allocation without having system wide privileges. To enable this, CKRM classes can be hierarchically subdivided into subclasses.
Each subclass gets its own share of the parent class' allocation. The user or workload associated with a subclass can create its own subclasses, change subclass shares, monitor subclass usage, effectively managing their allocation independent of each other and the system administrator.
The depth of the class hierarchy supported by CKRM is defined by the controllers. The default depth expected to be three though resource controllers will/should be written to support a reasonably larger number. Classes that are created deeper than what a resource controller can support, then that class will not have support for that resource controller. For example, if the CPU controller can only support a depth of 2, and the user creates a class /config/ckrm/depth1/depth2/depth3, then depth3 will not have CPU controller.
User interacts with CKRM through RCFS (Resource Control File System). A filesystem is a natural interface for representing and managing the hierarchy of classes offering several advantages:
RCFS is written as a configfs filesytem. The root of rcfs filesystem, typically mounted as /config/ckrm, represents the whole system. Each class is represented by a directory containing the following control files:
Each class can contain tasks that do not belong to any of its subclasses. To regulate and monitor such tasks, CKRM defines an implicit default subclass for each class. Default subclass shares its parent's name and class data structure.
e.g. if class_A contains tasks t1, t2 and t3 and defines subclasses class_A1 contains only t1, then t2 & t3 belong to class_A's default subclass.
The default subclass of the root of rcfs (/config/ckrm) is significant because it is present at kernel bootup, being statically defined by CKRM core, and contains, at least initially, /sbin/init. Having such a system wide default class allows CKRM to ensure that every task in the system always belong to a class.
Default classes are not explicitly represented by a separate subdirectory at any level of the hierarchy. Thus /config/ckrm/class_A/members represents tasks that belong to the default subclass of class_A (moving a task to class_A implicitly moves it to the class_A's default subclass). Default class is left with the resource that is not assigned to any subclass. Statistics shown at a class level are that of the default class.
Classes are created using mkdir/rmdir at the appropriate level of the rcfs filesystem hierarchy. Newly created directory is automatically populated with the control files. At the time of creation no tasks are associated with it, and gets populated when tasks get classified to it. Removing a class reclassifies all tasks in that class to its parent class.
min_shares is the minimum amount of resource that tasks of a class will get if they request it. It is up to the resource controller how they manage it. They can reserve the resource for that class or they can have internal logic that provides the minimum amount of resource. Unused portions of min_shares can be redistributed (work conservation) by the corresponding resource controller with a reasonably timely reallocation back to the class, should its demand rise later.
max_shares is the maximum amount of resource that a class can use. They can be either hard or soft, depending on the capability and semantics of the resource e.g. open file descriptor limits are always hard whereas a limit on the number of page frames given to a class could be configured to be either hard or soft. Classes can never consume more resources than a hard limit, regardless of the usage by other classes. Exceeding a soft limit is permitted if the resource is sufficiently free. Resources granted over the soft limit can be reallocated by the resource controller to other classes which increase their usage (while remaining under their limit).
min_shares and max_shares are represented by whole numbers in the /path/to/<class>/shares control file. The calculation of a class's share is done as follows. Each line of the /path/to/<class>/shares file represents one managed resource and its share values in the format
res=<res_name>,min_shares=<num>,max_shares=<num>,child_total_divisor=<num>
Absolute minimum amount of value of a class's resource is calculated by the ratio of its min_shares to its parent's child_total_divisor.
e.g. assuming there's only entry (say numtasks) in the shares file, a class hierarchy with the following values
and assuming absolute number of tasks for class A to be 50000, will result in the following guarantees (w.r.t absolute number of tasks)
To derive A's share (with respect to its peer classes), a calculation similar to the one done for a1, a2 can be done, using A's parent's child_total_divisor.
max_shares is the maximum amount of resource a class can use. No child of a class can have a limit that is greater than its child_total_divisor.
example above will result in the following limits (w.r.t to absolute number of tasks)
Setting new memory resource shares is done through
echo "res=mem,min_shares=<num>,max_shares=<num>,child_total_divisor=<num> > /path/to/<class>/shares
e.g. echo "res=mem,child_total_divisor=200" > /path/to/A/shares
changes A's memory child_total_divisor in the example above to 200 (from 80)
and results in changing the proportional shares of a1, a2 and A's default classes.
while echo "res=mem,min_shares=45" > /path/to/A/a1/shares
changes a1's minimum shares to 45/80 (from 20/80) and reduces the minimum shares
of A's default class to (80-45-5=30)/80.
A user can determine the shares of a class by reading the /path/to/<class>/shares file and parsing its contents as explained above. Default subclass shares at any level can be calculated by summing the shares listed in each of the visible subclasses shares file and subtract the sum from the parent class's corresponding values. Userspace tools can be written to assist with all these calculations.
Note: the reason for choosing the scheme above is to allow absolute values to be specified while retaining the flexibility of changing all subclass shares without requiring an atomic update to all their values. Another option considered and abandoned was to specify relative shares only (where the parent class's values would not be explicitly stated/modifiable but would be calculated by summing the guarantees of all children).
res=<resource name> identifies the resource controller. Changes to share values through writes and requests for shares through reads get passed on to each affected resource controller by the core. As usual, UNIX file permissions take care of access control to the shares file.
Shares for all the resources need not be specified for a class. If a resource's share is unspecified for a class, the class's tasks get their resource shares from the class's parent. In no class in the hierarchy has shares set, then the resources are shared according to the specific controller.
Note that min_shares and max_shares values at the root level (ex. /config/ckrm/shares) have no significance since there is no parent to get child_total_divisor value from. Similarly, child_total_divisor at the leaf classes have no significance since there is no children that can use it.
Statistics on resource use can be gathered from the 'stats' file in each class directory. To make portability and scripting easier the data is in plain text.
Currently syntax is not enforced on the stats file. Controllers return information they consider useful as strings.
A task can be manually classified into a class by writing its pid into the target class' members file as follows
echo "<pid>" > /path/to/class/members
The pid is a positive number for a normal task ID. Currently this is only form that is supported.
The UNIX file permissions on the members file in the chosen class determine whether or not the task that is writing the pid to the members file has the permission to reclassify a task. Also, non super-user task will not be able to reclassify tasks that are not owned by that user.
A special 'members' file is used instead of the class' directory so that permissions to join a task class can be configured separate from permissions to query statistics about the class.
A task can also get classified automatically if an optional Classification Engine is present, as described in Section 4.
Resource controllers are the kernel code that enforce the class-based control and supply the class-based statistics. They are typically implemented as patches to the existing controllers (or schedulers) with two primary design objectives
CKRM project currently provides resource controllers for the primary physical resources such as CPU (ticks), physical memory (page frames), block I/O (per-device bandwidth) and number of tasks controller. In future, additional controllers for virtual resources such as open files, shared memory segments are being considered as well.
Resource controllers need to register each managed resource separately. It is possible for one patch/module to regulate several related resources e.g. the controller providing class-based control over open files and shared memory segments could be the same but needs to register each of the resources separately.
Typically resource controllers will have private objects for each CKRM class. The Core patch provides data structures to associate this private data with the class objects it creates. When classes get modified (creation, deletion, tasks moving in and out, share changes, request for usage statistics), core invokes appropriate callbacks for each of the registered resources to do the necessary changes and return data for that resource. These callbacks and their related functions form a Core->Resource Controller API that is internal to the kernel.
The CKRM Core will provide helper functions for resource controllers to traverse the class hierarchy to update statistics lazily, calculate share values etc.
Resource controllers can be configured by writing resource specific config parameter through the interface they select. See relevant resource controller document for details on config parameters and how to modify them.
As described briefly in Section 1, Classification Engine is an optional component that is now implemented in the user space. CE can automatically classify tasks after specific kernel events (called reclassification events) such as exec, fork, setuid, setgid etc.,
CE uses Process Event Connector to get notification of the above mentioned process events and uses the task's specific information to classify the task according to some exiting user defined rules.
- Core is active as soon as the kernel is booted. - resource controller 1 registers - resource controller 2 registers : : - No task is classified, resource controllers handle tasks in default mode : : - User defines multiple classes - User sets shares for each of the resource classes defined - User manually moves some tasks to some of the newly defined classes and these tasks get regulated according to the new shares. : : : - User gets resource usage of different classes - User manually moves some tasks to different classes : :